文本分类中词语权重计算的改进
[12-01 19:55:00] 来源:http://www.jianzhu518.com 建筑信息化 阅读:9239次
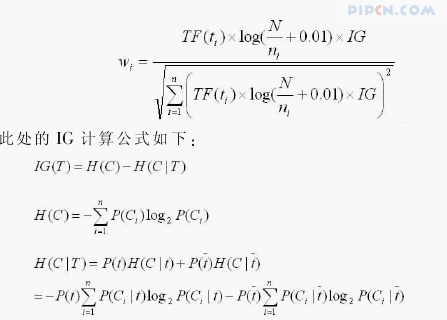
其中,P(Ci)表示类别(Ci)出现的概率,P(t)是特征T出现的概率,用出现过T的档数除以总文档数,表示出现T时类别Ci出现的概率。
还是采用上文第2节的小例子,先计算各词语对于分类的信息增益情况。

IG的值越高,表示特征项对于分类所能提供的信息量就越多,从表3中可以看出,IG的计算结果与我们主观判断的结果是相同的。t1只在类c1中出现,所以其对于分类的结果应该是最重要的,t3次之,而t2由于是三个类别中均出现过,所以其对于分类的结果是最不重要的,它对于分类的信息增益值也是最小的。再来看看将IG考虑进权重计算公式后,词语的权重,并与传统的权重计算公式的结果相对比。
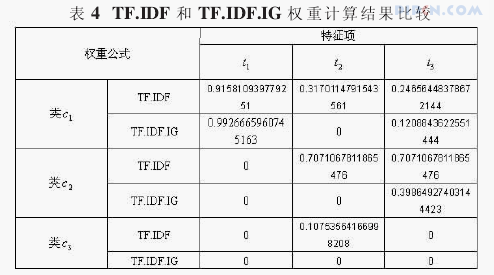
由表4中的权重计算结果可以看到,两种权重计算公式对于t1的分类能力都是给予肯定的。而对于t2,由于它在三个类别中均出现过,传统的TF.IDF的公式没有考虑到类别层次上,所以用传统公式计算时,它的权重是要大于t3的权重的。而在改进的公式中,明显可以看到t2对于三个类别都是没有分类能力的。
从上面的分析中,可以十分清晰地看到改进的TF.IDF.IG公式相对于传统公式的长处,以及其对于分类问题当中特征词权重计算的改善,结果表明这是可行的。
5实验及结果分析
为了进一步验证改进公式的有效性,在实际的分类问题中再次对比两个公式的分类结果。本文选用搜狗实验室提供的中文文本分类语料库中的数据来进行本次实验。
标签: 暂无联系方式 建筑信息化,建筑信息化
上一篇:企业预算管理系统的设计与实现